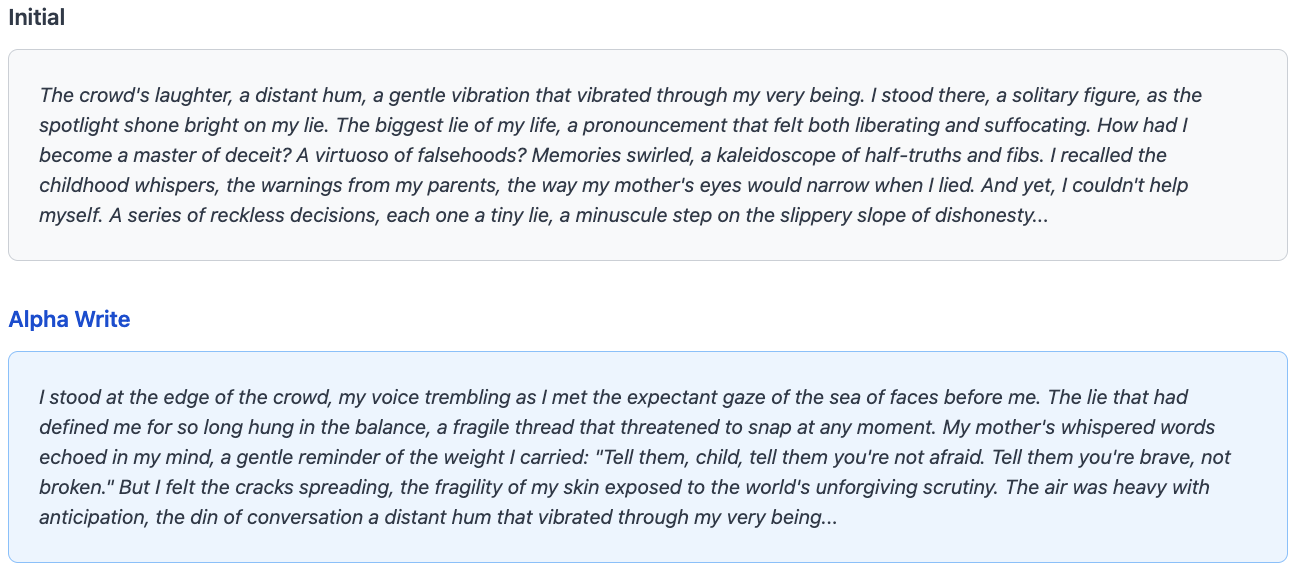
Large language models have demonstrated remarkable improvements in performance through increased inference-time compute on quantitative reasoning tasks, particularly in mathematics and coding. However, the creative domain—where outputs are inherently highly subjective and difficult to evaluate—has seen limited exploration of systematic approaches to scale inference-time compute effectively.
In this work, we introduce Alpha Writing, a novel framework for scaling inference-time compute in creative text generation. Inspired by AlphaEvolve and other evolutionary algorithms, our approach combines iterative story generation with Elo-based evaluation to systematically improve narrative quality. Rather than relying on single-shot generation or simple resampling, Alpha Writing creates a dynamic ecosystem where stories compete, evolve, and improve through multiple generations.
Our method addresses a critical gap in the field: while we can easily scale compute for tasks with clear correctness criteria, creative domains have lacked principled approaches for leveraging additional inference resources. By treating story generation as an evolutionary process guided by pairwise preferences, we demonstrate that creative output quality can be systematically improved through increased compute allocation.
We further demonstrate the scalability of these methods by distilling the enhanced stories back into the base model, creating a stronger foundation for subsequent rounds of Alpha Writing. This recursive cycle—where improved outputs become training data for an enhanced model that can generate even better stories—offers promising potential for self-improving writing models.
Methodology
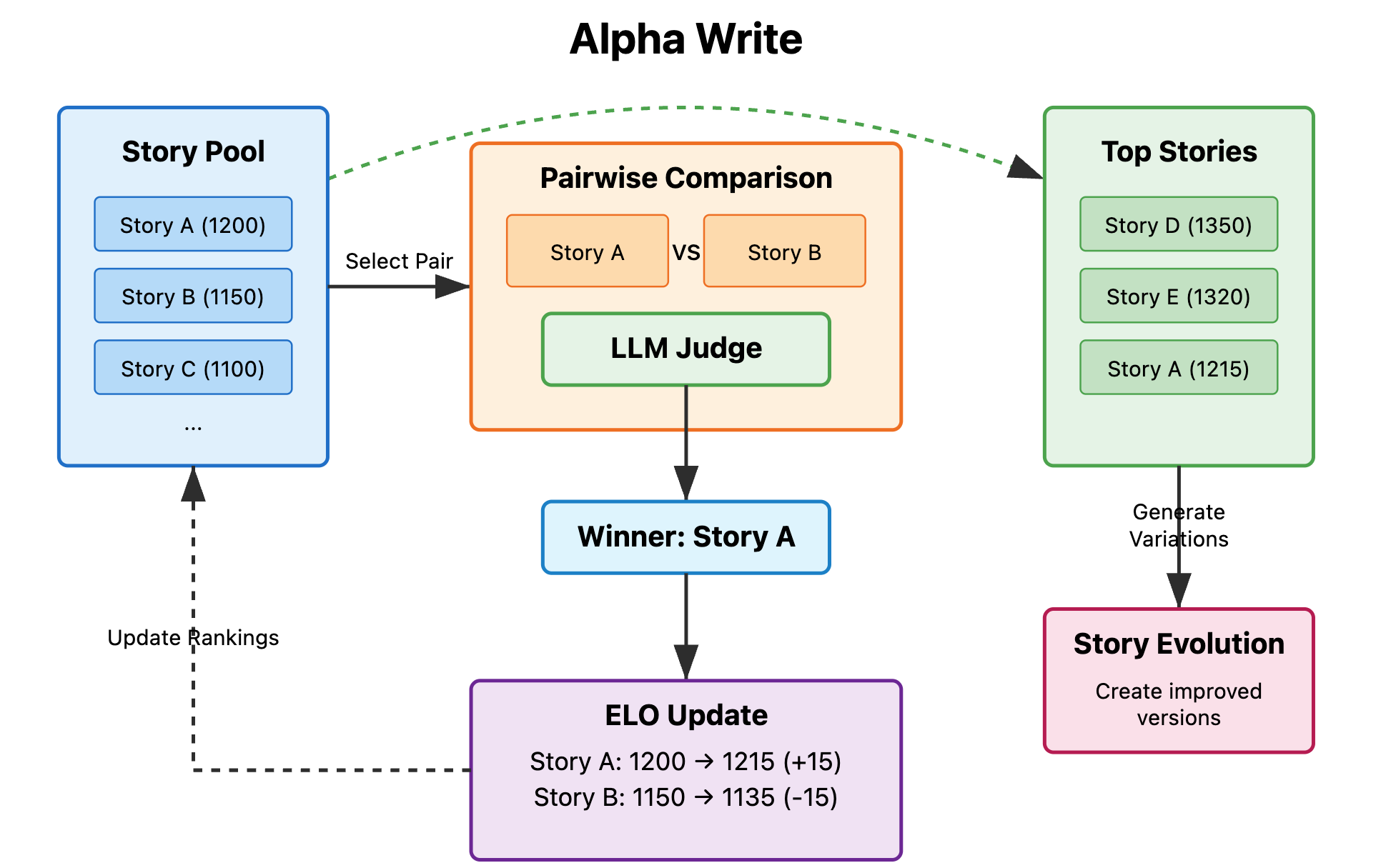
Overview
Alpha Writing employs an evolutionary approach to improve story quality through iterative generation and selection. The process consists of four main stages: (1) diverse initial story generation, (2) pairwise comparison using Elo rankings, (3) evolutionary refinement of top-performing stories, and (4) repetition of stages (2) and (3) across multiple generations to progressively enhance narrative quality.
Initial Story Generation
To establish a diverse starting population, we generate a large corpus of initial stories with systematic variation. Each story is generated with two randomized parameters:
- Author style: The model is prompted to write in the style of different authors
- Theme: Each generation focuses on a different narrative theme
This approach ensures broad exploration of the creative space and prevents early convergence on a single narrative style or structure.
Judging and Elo Ranking
Stories are evaluated through pairwise comparisons using an LLM judge. The judge is provided with:
- A detailed evaluation rubric focusing on narrative quality metrics
- Two stories to compare
- Instructions to select the superior story
The rubric improves consistency in judgments by providing clear evaluation criteria. Based on these pairwise comparisons, we update Elo ratings for each story, creating a dynamic ranking system that captures relative quality differences. We use base Elo of 1200 and K-factor of 32. For our experiments we use the same model as the judge and generator
Story Evolution
After establishing rankings through pairwise comparisons, we implement an evolutionary process to iteratively improve story quality:
1. Selection: Select top-performing stories as foundation for next generation
2. Variation Generation: Generate variants using randomly sampled improvement objectives (narrative structure, character development, emotional resonance, dialogue, thematic depth, descriptive detail, plot tension, prose style). Random sampling maintains creative diversity.
3. Population Update: Retain high-performers, replace lower-ranked stories with variants
4. Re-ranking: Fresh pairwise comparisons on updated population
5. Iteration: Repeat across generations, allowing successful elements to propagate
Evaluation Protocol
Evaluating creative output presents significant challenges due to subjective preferences and high variance in story content. Our evaluation approach includes:
- Model selection: Focus on smaller models where improvements are more pronounced
- Story length: Restrict to stories under 500 words to enable easier comparison
- Prompt design: Use open-ended prompts to allow models to demonstrate narrative crafting abilities
- Data collection: 120 preference comparisons per experiment to establish statistical significance
- Evaluation Protocol: Evaluators use the same rubric we provide to the LLM judge to score which of the two responses they prefer
Initial generations often exhibited fundamental narrative issues including poor story arcs and structural problems, making improvements through evolution particularly noticeable. We compare performance against initial model-generated stories and stories improved through repeated prompting.
We acknowledge that our evaluation methodology, while establishing statistically significant improvements, would benefit from more comprehensive data collection. We simply seek to demonstrate a statistically significant signal that this method works—quantifying the actual improvement is difficult and would require significantly more diverse data collection.
We found quality differences were subtle in opening lines but became pronounced in longer stories, where structural coherence and narrative flow showed clear improvement. However, evaluating these stories remains genuinely difficult—they diverge so dramatically in theme, style, and approach that determining which is “better” becomes largely subjective and dependent on reader preference.
Results
For evaluation we used Llama 3.1 8B and generated 60 initial stories, selected the top 5 performers, and created 5 variants of each. This evolution process was repeated for 5 generations
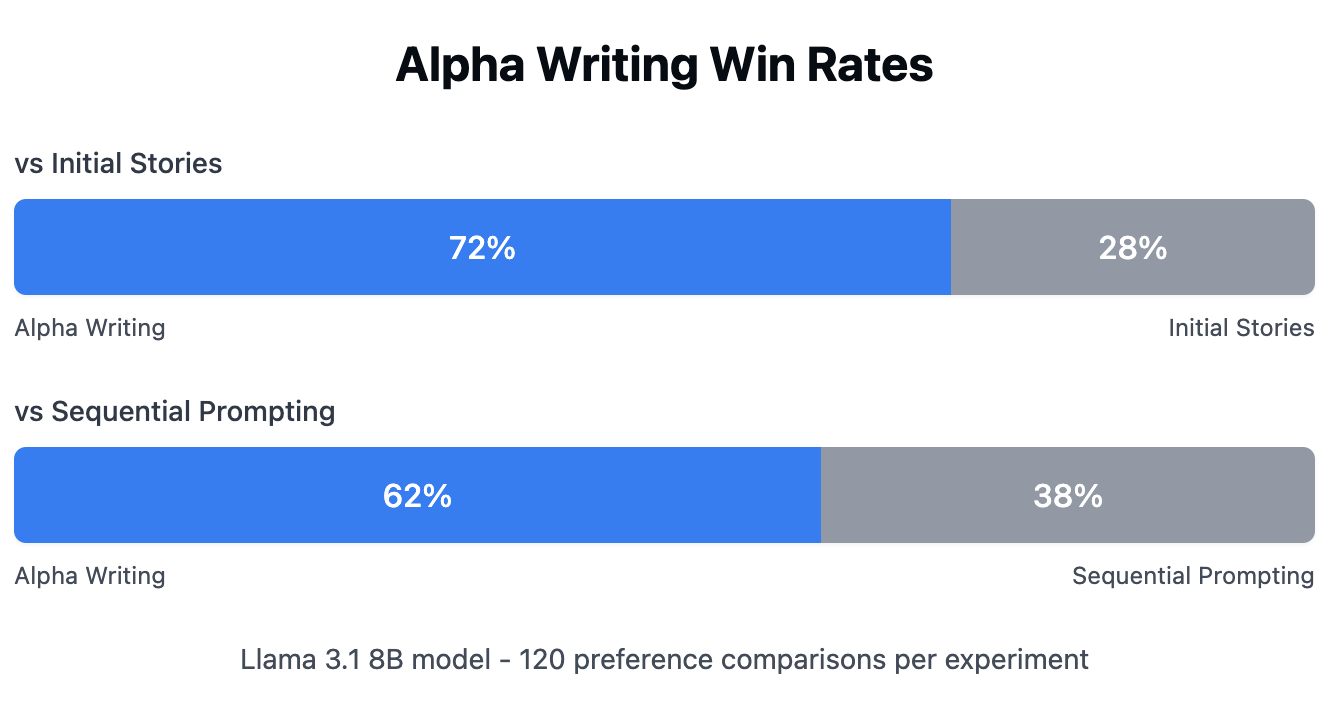
Alpha Writing demonstrates substantial improvements in story quality when evaluated through pairwise human preferences. Testing with Llama 3.1 8B revealed:
- 72% preference rate over initial story generations (95 % CI 63 % – 79 %)
- 62% preference rate over sequential-prompting baseline (95 % CI 53 % – 70 %)
These results indicate that the evolutionary approach significantly outperforms both single-shot generation and traditional inference-time scaling methods for creative writing tasks.
Recursive Self-Improvement Through AlphaWrite Distillation
An intriguing possibility emerges when considering inference scaling techniques like AlphaEvolve or AlphaWrite: could we create a self-improving loop through using inference scaling to improve results then distill back down and repeat?
The Core Concept
The process would work as follows:
- Apply AlphaWrite techniques to generate improved outputs from the current model
- Distill these enhanced outputs back into training data for the base model
- Reapply AlphaWrite techniques to this improved base, continuing the cycle
Experiments
We explored this concept through preliminary testing:
- Generation Phase: Ran AlphaWrite with 60 initial questions, top 5 questions per batch, 5 variations of each for 5 generations. Ran process 10 times generating 50 stories in total
- Selection: Identified the top 10 highest-quality stories of the final batch
- Fine-tuning: Used these curated stories to fine-tune Llama 3.1 8B
- Iteration: Repeated the process with the enhanced model
This recursive approach theoretically enables continuous self-improvement, where each iteration builds upon the strengths of the previous generation, potentially leading to increasingly sophisticated capabilities without additional human-generated training data.
Results
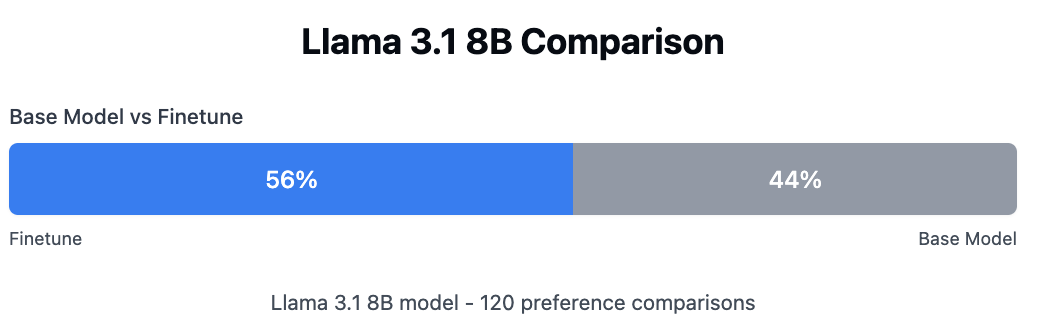
We observed a 56% (95 % CI 47 % – 65 %) preference rate over the base model. While this improvement falls within the statistical significance range for this experiment, collecting sufficient preference data to achieve statistical significance would be prohibitively expensive.
Limitations
Prompt Sensitivity: The quality and diversity of generated stories are highly dependent on the specific prompts used. Our choice of author styles and themes introduces inherent bias that may favor certain narrative approaches over others. Different prompt sets could yield substantially different results.
Evaluation Challenges: The subjective nature of creative quality makes definitive assessment difficult. Our 120 preference comparisons represent a small sample of possible reader preferences.
Convergence Risks: Extended evolution could lead to homogenization, where stories converge on particular “winning” formulas rather than maintaining true creative diversity. We observed early signs of this in later generations.
Beyond Creative Writing
The Alpha Writing framework extends far beyond narrative fiction. We’ve already employed it in drafting sections of this paper, demonstrating its versatility across writing domains. The approach can be adapted for:
Targeted Generation: By incorporating specific rubrics, Alpha Writing can optimize individual components of larger works—generating compelling introductions, crafting precise technical explanations, or developing persuasive conclusions. This granular control enables writers to iteratively improve specific weaknesses in their work.
Domain-Specific Applications: The framework naturally adapts to technical documentation, academic writing, marketing copy, and other specialized formats. Each domain simply requires appropriate evaluation criteria and judge training.
Model Enhancement: Perhaps most significantly, Alpha Writing offers a systematic approach to improving language models’ general writing capabilities. By generating diverse, high-quality training data through evolutionary refinement, we can potentially bootstrap better foundation models—creating a virtuous cycle where improved models generate even better training data for future iterations.
This positions Alpha Writing not just as a tool for end-users, but as potentially a fundamental technique for advancing the writing capabilities of AI systems themselves.
Conclusion
Alpha Writing demonstrates that creative tasks can benefit from systematic inference-time compute scaling through evolutionary approaches. Our results show consistent improvements over both baseline generation and sequential prompting methods, suggesting that the apparent intractability of scaling compute for creative domains may be addressable through appropriate algorithmic frameworks.
Code Repository: AlphaWrite on GitHub
Citation
@article{simonds2025alphawrite,
title={AlphaWrite: Inference Time Compute Scaling for Writing},
author={Simonds, Toby},
journal={Tufa Labs Research},
year={2025},
month={June},
url={https://github.com/tamassimonds/AlphaEvolveWritting}
}