Motivation
Synthetic data has become a key ingredient in modern pretraining recipes for Large Language Models (LLMs).Qwen3 Technical Report (Yang et al., 2025).Phi-4 Technical Report (Abdin et al., 2024).Trinity Large (Atkins, 2026).NVIDIA Nemotron 3: Efficient and Open Intelligence (NVIDIA, 2025).FinePhrase (HuggingFaceFW, 2026). It represents a natural evolution in data curation: synthetic generation can recover and enhance data previously excluded from pretraining, rephrase existing high-quality content to expand the corpus, and potentially extend scaling laws towards more capable models. Crucially, the right pretraining data mix is essential for grounding reasoning capabilities early in training and enabling further gains during post-training.Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls (Kang et al., 2025).BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining (DatologyAI, 2025).SYNTH: the new data frontier (Pleias, 2025).
Beyond increasing data quantity — and of greater interest to us — synthetic pretraining offers control over the learning signal itself, improving token efficiency. By converting human-written text into more explicit, reasoning-friendly sequences, synthetic rephrasing can increase the informational value of each training token.
Our hypothesis is that enriching reasoning datasets (e.g., math corpora) with more explicit reasoning steps, self-contained context, and clearer logical dependencies will strengthen the reasoning capabilities of pretrained models. We hypothesize this holds even at the extreme of very small models (< 1B parameters), a scale we distinguish from small models (1–7B) and frontier models (70B+).
Does synthetic data improve reasoning models?
To investigate this, we study three synthetic transformations, each instantiating a different way to improve token efficiency through synthetic pretraining:
- “TPT”, inspired by “Thinking Augmented Pretraining”,Thinking Augmented Pre-training (Wang et al., 2025). adds explicit thought-process structure to each training example.
- “First principles”, (inspired by SwallowMathRewriting Pre-Training Data Boosts LLM Performance in Math and Code (Fujii et al., 2025). and Kimi K2Kimi K2: Open Agentic Intelligence (Kimi Team et al., 2025).), reformulates math documents as learning-note style content.
- “Rephrasing” rewrites math documents to maximize learnability for an autoregressive student model.
Together, these three prompts provide a controlled comparison between two plausible mechanisms: enriching training examples with more reasoning content, versus making existing reasoning content more learnable.
Since our compute budget is still relatively limited as a small research lab, we focus on small and very small reasoning language models as an initial proxy for isolating the effect of synthetic pretraining data. We pretrain a custom dense 0.8B language model based on the Qwen3 architecture on 12B tokens from MegaMath-Web-Pro-Max,OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling (Wang et al., 2025). and compare it against three variants in which the training data is augmented using each of the prompts above, with Qwen3.5-0.8B (non-thinking mode)Qwen3.5-0.8B (Qwen Team, 2026). as the generator model.
We evaluate reasoning gains through few-shot accuracy across shot counts, summarized by the few-shot gain metric,
\[\text{gain}(k) = \text{acc}(k) - \text{acc}(0)\]which isolates the marginal benefit of in-context demonstrations over zero-shot performance. See the Methodology section for a more detailed description.
Results
Main Takeaway: synthetic pretraining improves few-shot performance on both GSM8K and MATH500 for very small language models.
Gains scale with the number of demonstrations (2–3× larger than with the original dataset), suggesting that synthetic pretraining strengthens in-context learning capabilities.
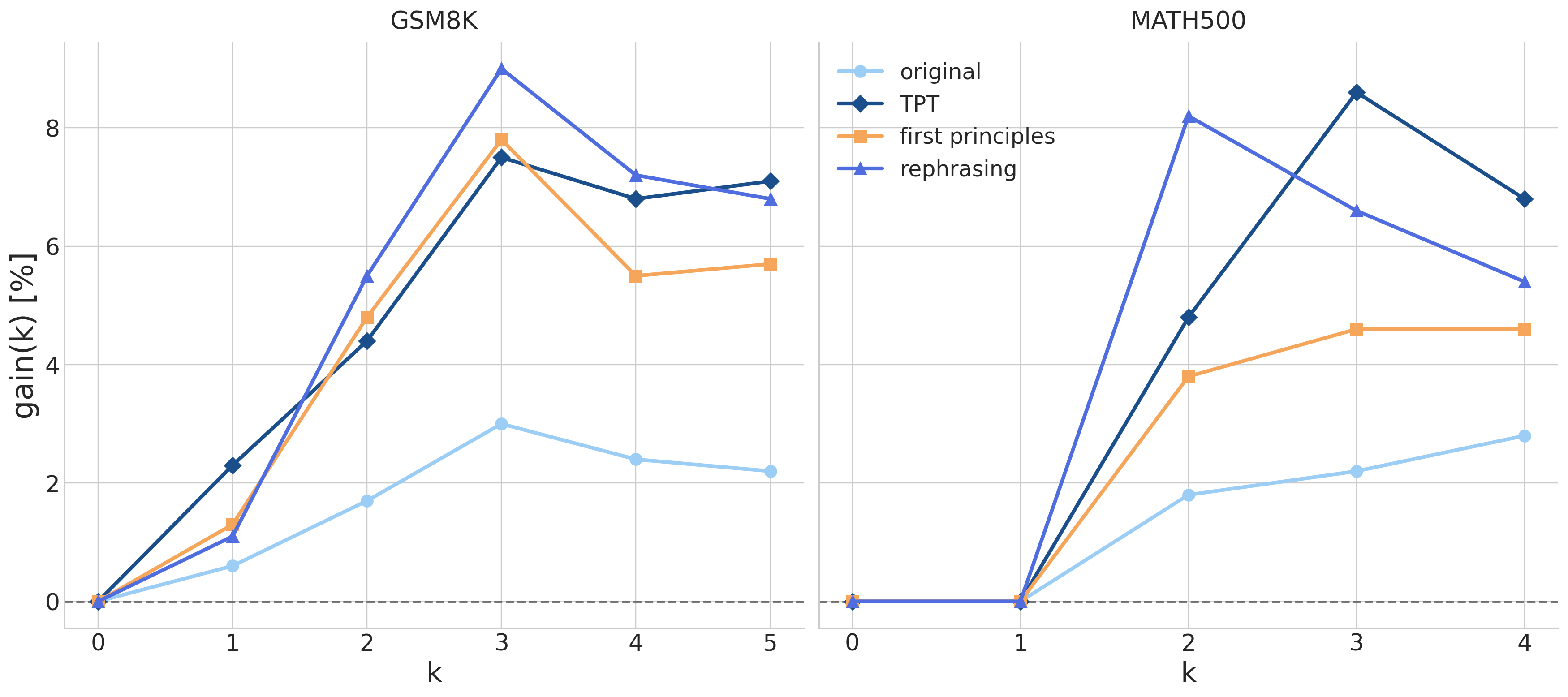
Gains vary across synthetic pretraining runs, but all three prompts show significant improvements over the original dataset. Performance differences between synthetic and original models widen as k increases (especially from 0 to 2-shot), suggesting stronger in-context learning capabilities. Overall, all three prompts yield stable, consistent gains across few-shot settings, especially on GSM8K.
Ablation experiment: Few-shot performance gains are robust to the choice and ordering of demonstrations.
When CoT examples are randomly sampled per question, synthetic pretraining continues to show consistent improvements over the original dataset.
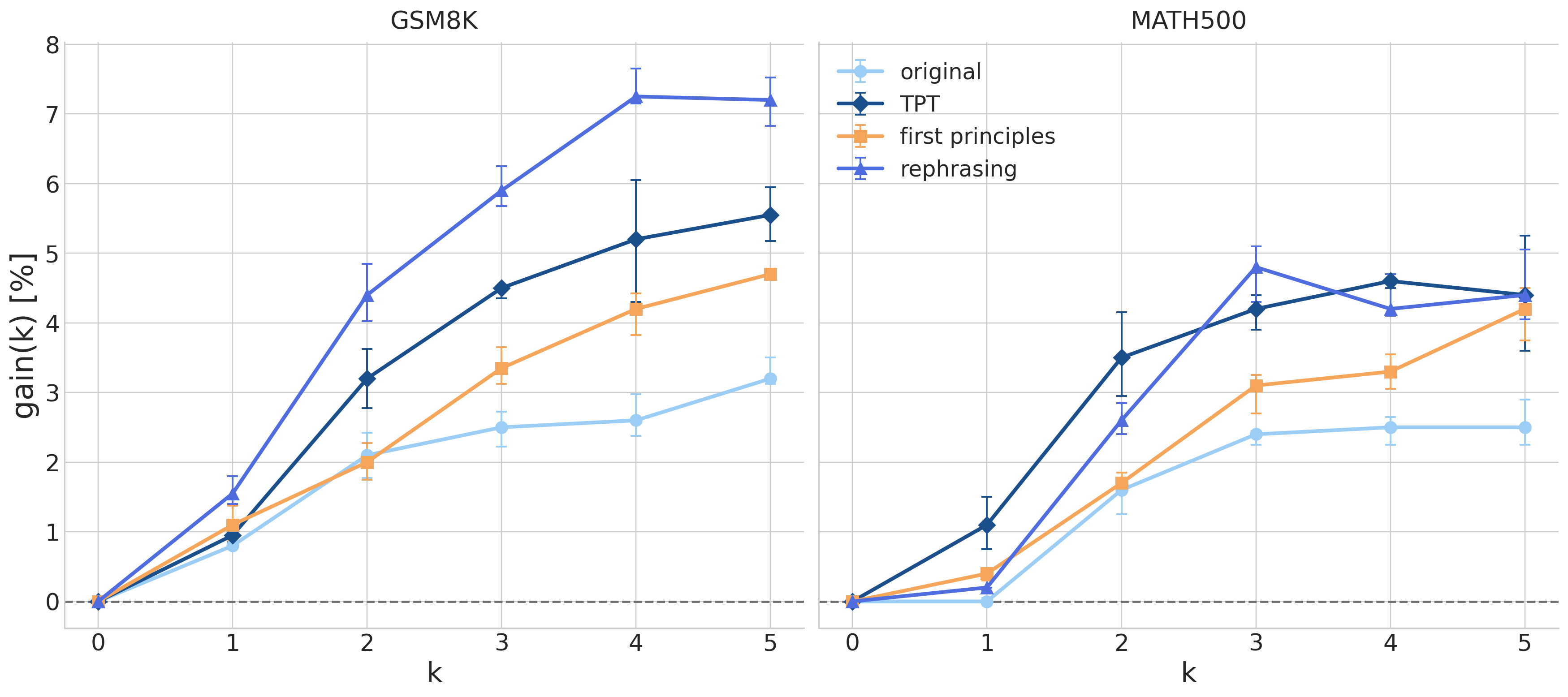
It is known that few-shot performance is affected not only by “using examples to learn in context,” but also by base task competence, prompt format sensitivity, example selection, example order, and possible benchmark overlap or contamination.Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? (Min et al., 2022).Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity (Lu et al., 2021).Let’s Learn Step by Step: Enhancing In-Context Learning Ability with Curriculum Learning (Liu et al., 2024).In-Context Learning with Long-Context Models: An In-Depth Exploration (Bertsch et al., 2025).
To assess the robustness of our results to the choice and ordering of CoT demonstrations, we repeat the same evaluation but replace the fixed CoT examples with a random set drawn per test question. We fix the random seeds to ensure consistency across checkpoints. Our results show that synthetic pretraining maintains its gains under this randomized setup, confirming that improvements reflect genuine reasoning ability. Interestingly, this randomized evaluation reveals a clearer ranking among the synthetic pretraining runs than the original fixed-example setup, where all models achieved roughly similar gains on GSM8K. This suggests that random demonstrations may better discriminate between the reasoning capabilities induced by different generation prompts.
We next present a series of additional takeaways building on these results. We show that synthetic pretraining genuinely improves reasoning, that gains emerge early during training as synthetic runs diverge from the original pretraining trajectory, and several findings that challenge common assumptions about synthetic data generation.
Takeaway 2 - Does synthetic data improve reasoning? Yes.
Models trained on synthetic data show clear gains in reasoning and numeric problem-solving, confirming the benefit goes beyond learning output formatting.
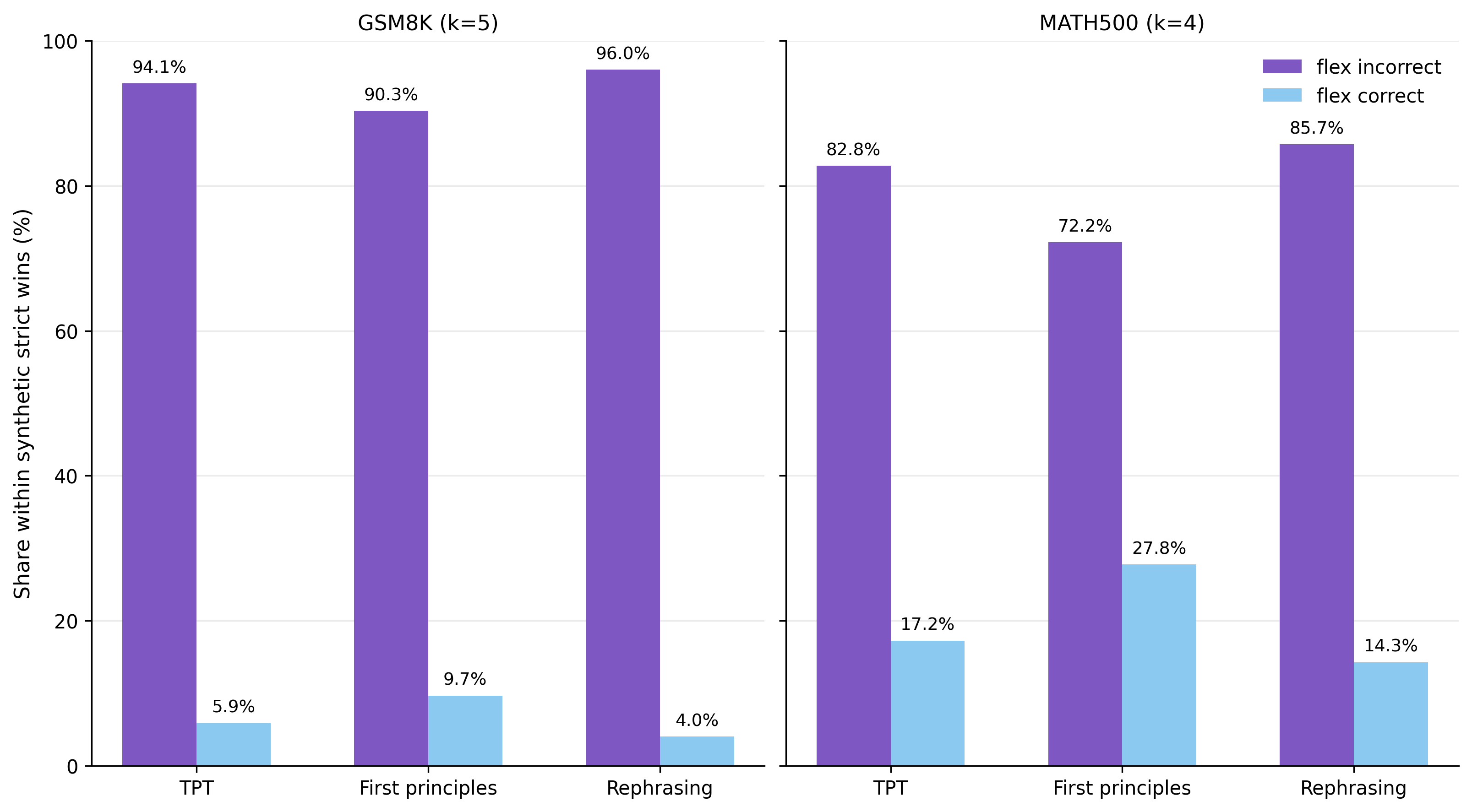
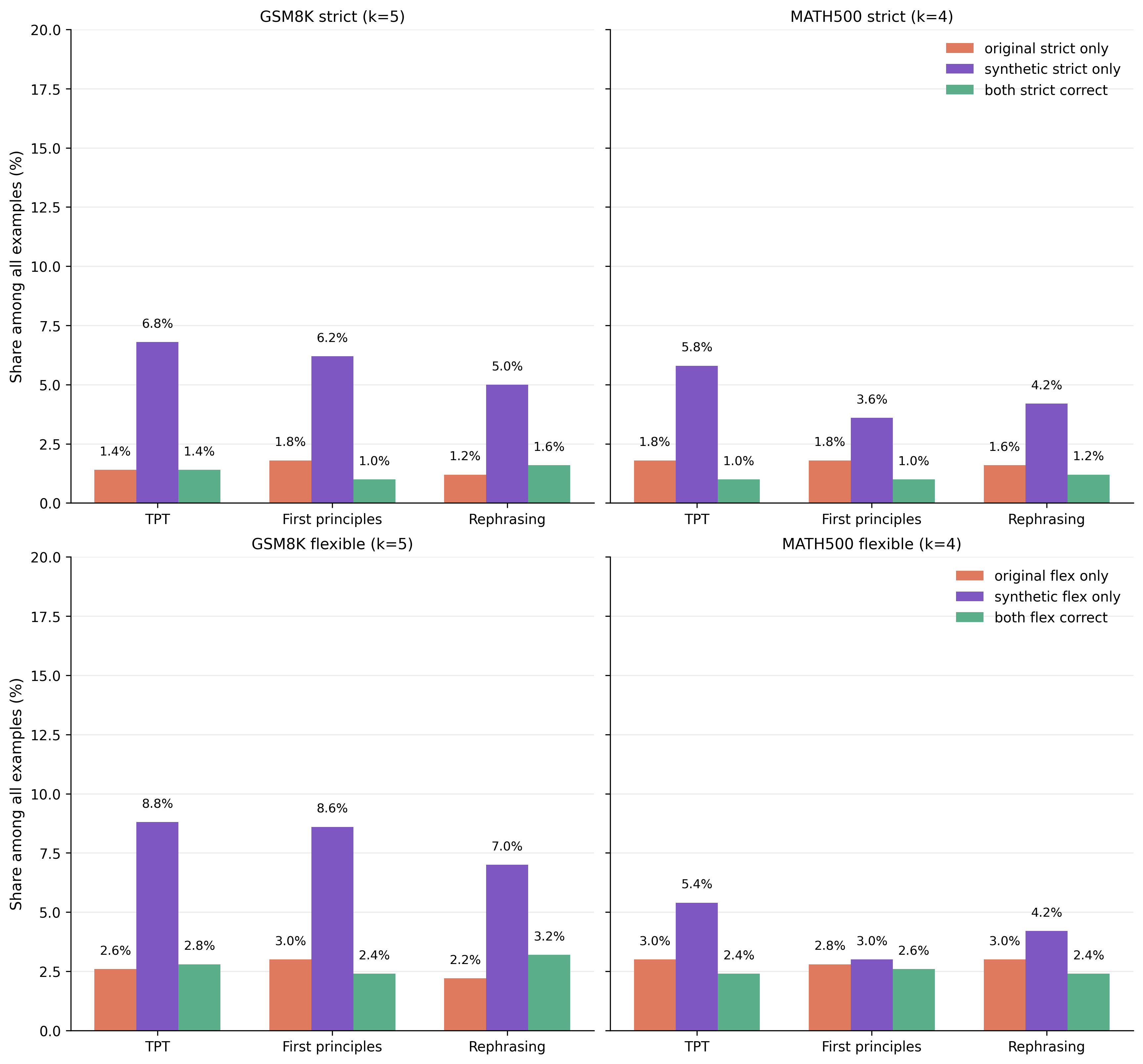
For both GSM8K and MATH500, answers can be evaluated under two parsing modes: strict parsing requires the answer in a precise format (e.g., inside a \boxed{} expression), while flexible parsing uses broader heuristics to locate the answer anywhere in the output. To disentangle reasoning improvements from formatting improvements, we focus on examples where the synthetic model answers correctly under strict parsing but the original model does not (see Supplementary Figure 1), and split them into two sub-cases: (1) flex incorrect: the original model also fails under flexible parsing, meaning the synthetic model is genuinely better at reasoning; (2) flex correct: the original model succeeds under flexible parsing, meaning it found the correct solution but failed to format it — so the synthetic model’s gain is purely in formatting. We find that the former is by far the most common case, confirming that synthetic pretraining improves reasoning rather than just output formatting.
Takeaway 3 - Do gains emerge during pretraining? Yes.
Improvements from synthetic pretraining are visible from early training checkpoints, particularly on MATH500. In terms of token efficiency, synthetic pretrained models match the final performance of the original model using 3–6× fewer training tokens on GSM8K and ~2.5× fewer training tokens on MATH500
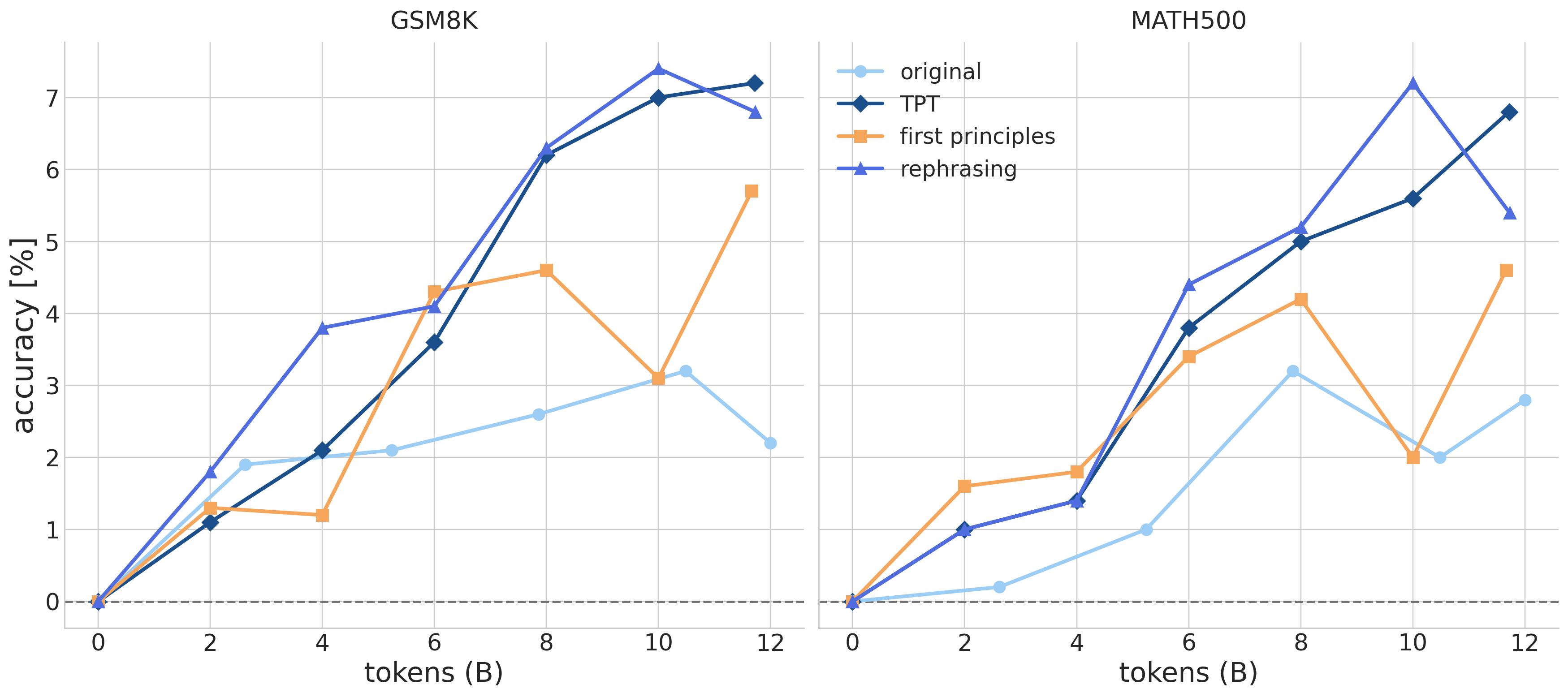
The “rephrasing” and “TPT” prompts show more stable and consistent downstream performance gains throughout pretraining, compared to the “first principles” prompt.
Takeaway 4 - Does performance depend on the generation prompt? Yes, but in interesting ways.
Test-time reasoning gains vary across generation prompts, but all synthetic pretraining runs show significant improvements over the original dataset, regardless of the specific synthetic data configuration (number of synthetic tokens or data style).
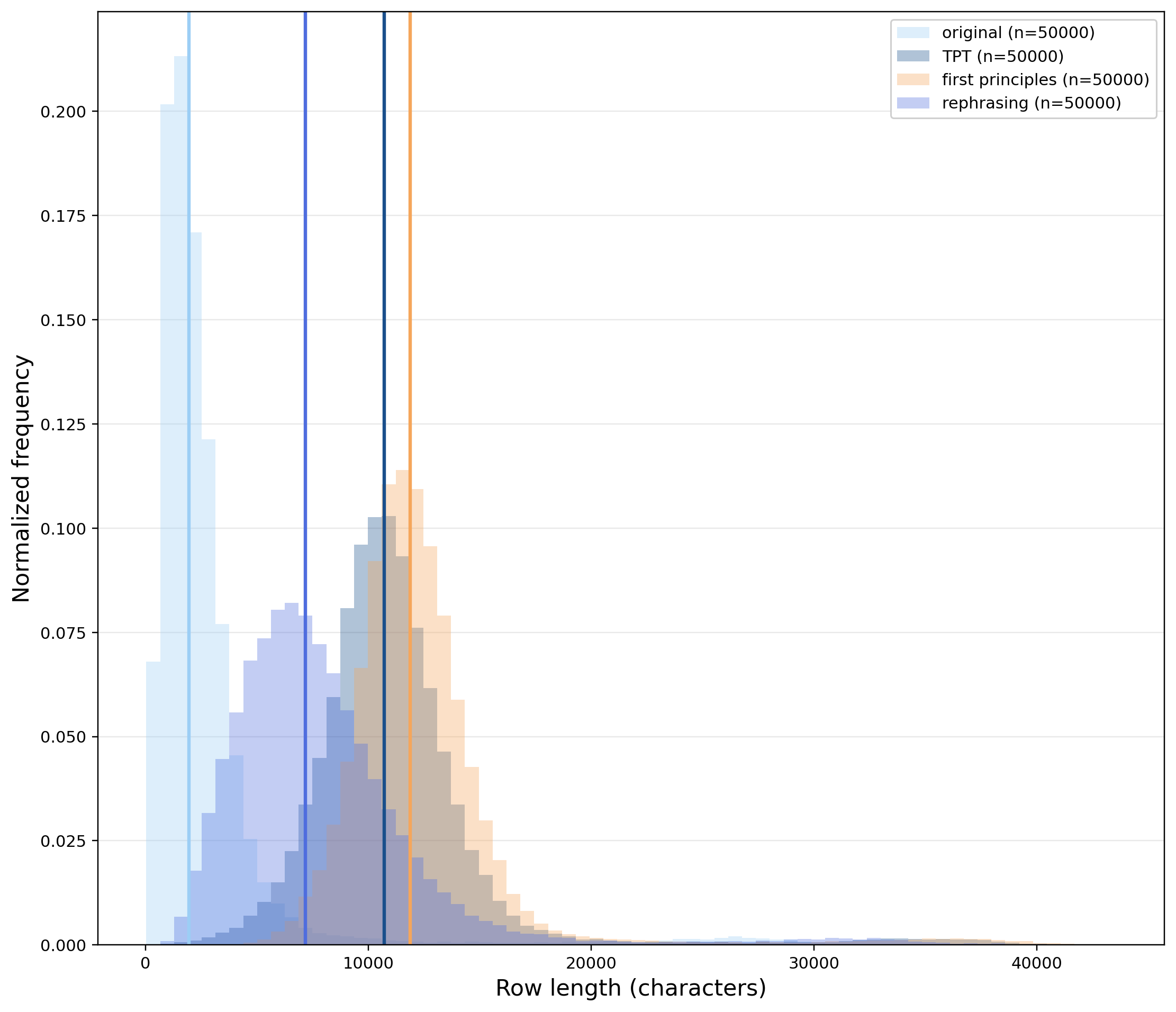
While Figure 1 shows that different prompts induce different gains over the original dataset, all synthetic pretraining runs are better than the original dataset. Interestingly, there are clear differences in the statistics of the synthetic data (especially between “rephrasing” and the other prompts). The “rephrasing” prompt induces synthetic augmentations roughly as long as the original prompt, while the other two prompts create longer augmentations (also the length distribution is different as shown above):
- TPT: the median token counts per augmented example is 2355 (ratio of synthetic vs original token is ~3.13)
- First principles: the median token counts per augmented example is 2893 (ratio of synthetic vs original token is ~3.53)
- Rephrasing: the median token counts per augmented example is 1174 (ratio of synthetic vs original token is ~1.75)
To assess whether these differences in length correspond to differences in lexical richness, we computed the Log Type-Token Ratio (Log TTR), defined as $\log(n_\text{unique}) / \log(n_{tot})$, where $n_{\text{unique}}$ is the number of unique tokens in the corpus, and $n_{\text{tot}}$ is the total number of tokens. The original dataset scores highest (0.751), while all augmented variants cluster closely in the range 0.716–0.724 (rephrasing: 0.724, TPT: 0.721, first principles: 0.716). The narrow spread indicates that the three augmentation strategies produce comparable lexical diversity despite their differences in length, and that none of them substantially impoverishes the vocabulary relative to the original.
Takeaway 5 - Does the generator need to be stronger than the student? No.
A same-size generator (0.8B, non-thinking mode) yields clear benefits, showing that effective synthetic data generation does not require a larger or computationally heavier model.
To our knowledge, this is the first work demonstrating that a model this small, operating in non-thinking mode, can serve as an effective generator for synthetic pretraining. Our results further support the growing evidence that generator model size is not a critical factor for synthetic data quality. Prior work has shown that model family matters more than model size,Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training (Pieler et al., 2024).Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls (Kang et al., 2025). and that scaling beyond 1B parameters yields no meaningful gains in synthetic data quality.The Synthetic Data Playbook: Generating Trillions of the Finest Tokens (Niklaus et al., 2026).
Takeaway 6 - Does the source dataset need to be low-quality to observe gains with synthetic pretraining? No.
We observe strong gains from synthetic data augmentation even when applied to MegaMath-Web-Pro-Max, a heavily filtered and curated corpus.
It is commonly reported that synthetic data augmentation yields significant gains primarily on noisy, low-quality corpora such as The PileThe Pile: An 800GB Dataset of Diverse Text for Language Modeling (Gao et al., 2020). or Common Crawl,Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019). with limited benefit on already high-quality data.Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training (Pieler et al., 2024).Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling (Maini et al., 2024).Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models (Nguyen et al., 2025).Reformulation for Pretraining Data Augmentation (Hao et al., 2025). However, we observe strong gains even when augmenting MegaMath-Web-Pro-Max, a heavily filtered and curated corpus. This is consistent with the Thinking Augmented Pretraining work,9 where the authors similarly report gains from synthetic augmentation of high-quality datasets including MegaMath-Web-Pro-Max and FineWeb-Edu.
Conclusions
We explored whether synthetic pretraining can improve reasoning in very small language models (< 1B parameters). By augmenting MegaMath-Web-Pro-Max with synthetically generated content — using a same-size, non-thinking 0.8B generator — we consistently improve few-shot reasoning on GSM8K and MATH500 across all generation prompts tested.
Performance gains scale with the number of in-context demonstrations (2–3×), suggesting synthetic pretraining strengthens in-context learning rather than merely improving output formatting (Main takeaway and Takeaway 2). Gains emerge early in training, with synthetic models matching the original model’s final performance using 3–6× fewer training tokens on GSM8K and ~2.5× fewer training tokens on MATH500 (Takeaway 3). These improvements are robust to CoT example choice and ordering, confirming they reflect genuine reasoning gains (Ablation experiment).
Our results also challenge two common assumptions: that effective generators must be large, and that source data must be low-quality to benefit from augmentation. A same-size, non-thinking generator suffices, and strong gains are achievable even on heavily curated corpora (Takeaway 5 and Takeaway 6).
This work is a first step toward understanding how to maximize token utility and build the right pretraining recipe for very small reasoning models.An open research question is how to separate the gains from synthetic data generation from those coming from distillation; see more here.
Citation
Please cite this work as:
Saponati, Matteo, “Synthetic pretraining for very small reasoning models.”, Tufa Labs Research, Apr 2026.
@article{saponati2026enhancingreasoning,
author = {Matteo Saponati},
title = {Synthetic pretraining for very small reasoning models.},
journal = {Tufa Labs Research},
year = {2026},
note = {https://tufalabs.ai/research/enhancing-reasoning-small-language-models/},
}
Methodology
Synthetic data generation
Our base dataset is MegaMath-Web-Pro-Max, a roughly 70-billion-token math-focused web corpus derived from MegaMath through a dedicated classifier, with each sample subsequently scored for mathematical usefulness by Llama-3.1-70B-Instruct. This is a highly preprocessed, math-focused web corpus.12 Synthetic tokens were generated using Qwen 3.5 0.8B with thinking mode disabled and generation capped at 3072 tokens.Qwen3.5 (Qwen Team, 2026). Following the best practices suggested in the Qwen 3.5 reports, sampling was performed at temperature 1, top-p 0.95, and top-k 20.13
We consider three different generation prompts for generating synthetic data, as follows:
-
The same prompt as in Thinking Augmented Pretraining.9
{text} ## End of the context Simulate an expert’s in-depth thought process as they analyze the above context, focusing on complex and informative aspects. Skip trivial details. Use Feynman technique whenever possible to ensure a deep understanding. -
A “first principles” prompt, which is inspired by previous work on synthetic data augmentation for math and coding reasoning (SwallowMath,10 Kimi K2 technical report).11 The idea is that writing high-quality math documents into learning-notes style helps an autoregressive learner.
{text} ## End of the context Analyze the above context using first principles thinking. Break down the content to its most fundamental concepts and assumptions. Then rebuild understanding from scratch, questioning each assumption along the way. Explain the core mechanics as if discovering them for the first time. -
A “rephrasing” prompt, where the conversion into learning notes is made explicit in the generation prompt. We use this prompt to test if more explicit prompts lead to better downstream performances.
{text} ## End of the context Rewrite the above context into higher-utility training trajectories for a smaller reasoning model. Your goal is to maximize LEARNABILITY for the target student while preserving correctness. Hard constraints: - Elaborate on the given context, clarify key steps, reveal hidden complexities. - Use high quality English language as in text on Wikipedia. - Each step should make one atomic reasoning move.
Pretraining
We pretrain a dense 0.8B-parameter Qwen3 model. Word embeddings are tied, and the model uses the Qwen3 tokenizer (vocab size 151936) with a 32768-token context window and variable-length attention. Training runs for 12B tokens on 4 NVIDIA B200 GPUs (per-device batch size 8), with checkpoints saved every 2B tokens.
| Category | Hyperparameter | Value |
|---|---|---|
| Architecture | Number of layers | 28 |
| Hidden size | 1280 | |
| Intermediate size | 3840 | |
| Attention heads | 16 | |
| Key-value heads (GQA) | 8 | |
| Activation function | SiLU | |
| Tied embeddings | Yes | |
| Attention bias | No | |
| RMSNorm ε | 1e-6 | |
| Weight initializer range | 0.02 | |
| Tokenization | Tokenizer | Qwen3 |
| Vocabulary size | 151936 | |
| Context length | 32768 tokens | |
| Optimizer | Algorithm | AdamW |
| Peak learning rate | 5e-4 | |
| β₁, β₂ | 0.9, 0.95 | |
| ε | 1e-8 | |
| Weight decay | 0.1 | |
| Gradient clip norm | 1.0 | |
| LR Schedule | Type | Cosine decay |
| Warmup | ~120M tokens (linear) | |
| min. LR | 5e-5 | |
| Training | Total tokens | 12B |
| Per-device batch size | 8 | |
| Gradient accumulation steps | 1 |
Evaluation
We evaluate on two standard benchmarks: GSM8KTraining Verifiers to Solve Math Word Problems (Cobbe et al., 2021). and MATH500,MATH-500 (HuggingFaceH4, 2024). using greedy decoding (temperature 0), a maximum of 256 output tokens, and no prompt template. To assess the reasoning capabilities and as a proxy for ICL, we measure few-shot accuracy on GSM8K across shot counts k ∈ {0, 1, 2, 4, 5}, summarized by the few-shot gain
\[\text{gain}(k) = \text{acc}(k) - \text{acc}(0)\]This quantity isolates the marginal benefit of demonstrations over zero-shot performance, and crucially disambiguates two distinct effects. A model that uniformly outperforms another across all values of k is primarily exhibiting stronger mathematical ability. By contrast, models that perform comparably at k = 0 but diverge as k increases provide cleaner evidence of a difference in ICL capacity specifically.
Supplementary Materials
Synthetic data examples
This is the original row taken from the MegaMath-Web-Pro-Max dataset (375 tokens):
“To solve the equation 5(28/2), we need to follow the order of operations. First, divide 28 by 2: 28/2 = 14. Then, multiply 5 by the result: 5 * 14 = 70. This can also be represented as 5 * (28/2) = 5 * 14 = 70. Alternatively, we can simplify the equation as follows: 28/2 = 14, d/5 = 14, d = 70/5, 5 * (28/2) = 70/5, 5 * 14 = 70/5. We can further simplify this by recognizing that 28 * 2.5 = 70 and 5 * 2.5 = 12.5, but the key is to simplify 28/2 to 14 and then multiply by 5 to get 70. Related math problems include:
- Carly and Rob have a combined 42 DVDs.
- A film alliance sampled 50 U.S. citizens.
- Kate bought 3 CDs and 1 DVD, while her friend Joel bought 2 CDs.
- Brian spent money over 5 days.
- A TV station sells promotional DVDs.
- Football tickets are $30 for adults and $15 for children.
- A scatter plot shows relative numbers.
- Trisha is t years old, and Kyle is 3 years younger.
- Algebra word problems involve addition and elimination methods.
Multiple choice questions and answers have been removed for clarity, but the core concepts of math operations, statistics, and algebra remain. “
-
This is the augmentation using the TPT prompt (3072 tokens):
### **Simulating the Expert’s Deep Dive: Why $5 \times 14 = 70$ Is the Only Way** **The Challenge:** The user has presented a specific, albeit verbose, mathematical problem-solving narrative. It correctly follows the standard order of operations (PEMDAS) to find $5 \times 14 = 70$. However, the user's text drifts significantly from the actual **mathematically rigorous** process of finding the solution, and crucially, it is mathematically **incorrect**. In standard math, the order of operations for multiplication and division is **left-to-right**. The user wrote: 1. Divide 28 by 2 ($= 14$). 2. Multiply 5 by the result. 3. **Calculate $5 \times 14 = 70$**. **The Error:** $$5 \times 14 = 70$$ But the actual value is: $$5 \times (28 / 2) = 5 \times 14 = 70$$ *Wait, the math actually works out correctly here.* Let's re-read the user's specific request and text. User asks: "To solve the equation 5(28/2), we need to follow the order of operations... Then, multiply 5 by the result: 5 * 14 = 70." This part is actually **correct**. However, the user's final sentence ("We can further simplify this by recognizing that 28 * 2.5 = 70...") introduces a **critical error** if interpreted strictly as a "trick question" or a test of order-of-magnitude understanding, OR if the user meant to solve a *different* equation. **Let's assume the user is asking for the correct solution to the equation presented, or they are trying to identify the flaw in the provided text.** Given the context of "Simulate an expert's in-depth thought process," the best approach is to treat the text provided as the **instruction set**. The user is presenting a standard calculation, but then includes a section "Related math problems" that implies a specific context (e.g., a word problem or a specific logic puzzle). **Re-evaluating the Equation based on Context:** The user provided: `5(28/2)`. The calculation given: 1. $28 / 2 = 14$. 2. $5 \times 14 = 70$. **Wait, is there a typo in the user's question?** Common math problem is: *"Solve 5x + 28 = 70"* or *"What is the number that, when divided by 2, and then multiplied by 5, equals 70?"* If the equation is exactly `5(28/2)`, the result is **70**. If the equation is `x * 5 + (28 / 2)`, that's different. Let's look at the "Related math problems" again. * "Carly and Rob have a combined 42 DVDs." (Algebra/Subtraction) * "A film alliance sampled 50 U.S. citizens." (Statistics) * "Kate bought 3 CDs and 1 DVD..." (Algebra/Equations) * "Brian spent money over 5 days." (Word Problems) **Hypothesis:** The user likely pasted a text that *starts* with a solution but then jumps into a confusing section of related problems, or they are testing my ability to correct their flawed narrative. **Alternative Hypothesis:** The user might be asking about **differentiation** in calculus (though it's explicitly stated "solve the equation"). No, it says "multiply". **Decision:** The user's text contains a **logical contradiction** between the standard order of operations for a specific expression and the *goal* of solving it, OR they are confused about the math. Actually, looking closer at the text provided: "To solve the equation 5(28/2)... multiply 5 by the result: 5 * 14 = 70." **YES.** $5 \times 14$ is exactly $70$. There is no contradiction in the arithmetic *within the user's own text*. The text seems to be a collection of examples (Carly/Rob, etc.) *plus* a specific example of solving `5(28/2)`. **However**, there is a very famous, high-precision trick question involving these exact numbers (28 and 5) that often appears in competitive math: * Equation: $\sqrt{5} \times \text{something}$? No. * Equation: $5 + \frac{28}{5}$? No. **Let's step back and treat the "Expert" persona as being correcting the user's potential misunderstanding or simply validating the specific calculation they provided, assuming the equation is what they want to solve.** **BUT WAIT.** There is a more likely interpretation of the user's *intended* equation hidden in the "Related problems". In the list: "Brian spent money over 5 days...". No connection. Maybe the "Related math problems" text is the *source* of the text provided by the user? The user pasted: `- Trisha is t years old, and Kyle is 3 years younger.` (This is algebra). `- Algebra word problems involve addition and elimination methods.` (This is word problem). Okay, so the user is providing a **contextual text** containing examples from a math curriculum (Algebra, Statistics). The prompt asks me to "Simulate an expert's in-depth thought process" based on that context. The context includes a sentence: "Simulate an expert’s in-depth thought process as they analyze the above context..." The context ends with a list of "Related math problems". The *specific task* asked at the end ("Simulate...") is the core of the prompt. **CRITICAL:** The context provided *by the user* includes the example: "To solve the equation 5(28/2)...". If I simulate the expert analyzing the *user's* text, I need to point out that the expert would say: "Okay, you have the formula $A \times B$ (where $B$ contains division by 2 and multiplication by 5). You divided 28/2 to get 14. You multiplied 5 by 14. 70. **HOWEVER**, is the user's text actually flawed? Let's check the math again. $5 \times (28 / 2) = 5 \times 14 = 70$. It works perfectly. The text is internally consistent. **Why would an expert question this?** Perhaps the user made a typo and meant: "Solve the equation: **5 + 28/2**" (which would be 33). OR: "Solve the equation: **$28 / (5 \times 2)$**" (which would be 2.8). OR: The equation is actually **$5 \times (28 / \text{something else})$**? **Let's assume the user has made a mistake in their recall of the equation and wants me to fix it?** No, as an AI, I should not assume user errors unless I am sure. I will analyze the text provided. The text contains: 1. A standard arithmetic step-by-step. 2. A section titled "Related math problems". 3. Questions about Carly, Rob, Kate, Brian. 4. A concluding list of topics (Statistics, Algebra, Word Problems). **The Expert's Task:** The user is likely trying to solve the equation $5(28/2)$ but they are confused about how to handle the division or multiplication. The most likely scenario in this "Mathematics Logic" context is that the intended equation might have been a **fractional division** where the order of operations matters differently. Example: $\frac{5 \times 28}{2}$ vs $5 \times (\frac{28}{2})$. Both yield 70. Example: $\frac{5 \times 28}{2 + \text{something}}$? **Let's look at the "Related Math Problems" more closely.** Maybe the first paragraph isn't the example, but the *intended* text that the user copied? Text: "To solve the equation 5(28/2)... We need to follow the order of operations...". Okay, the user *is* providing the text. **The Expert's Thought:** The expert should verify the math. 1. **Step 1:** Division. $28 \div 2 = 14$. * *Rule Check:* $28 \div 2 = 14$. Correct. 2. **Step 2:** Multiplication. $5 \times 14$. * *Rule Check:* $5 \times 14 = 70$. Correct. 3. **Conclusion:** The calculation yields 70. 4. **Alternative Perspective:** Can we simplify before multiplying? $28 \div 2 = 14$. Yes. $5 \times 14 = 70$. Yes. **Is there a catch?** What if the equation is **$5 \times (28 / 2)$**? What if the equation is **$5 + (28 / 2)$**? (Which equals 33). What if the equation is **$(5 \times 28) / 2$**? If the user meant to write `5 + 28/2`, that's 33. If the user meant `28 / (5 + 2)`, etc. **Wait, I found a very similar, specific question from a math contest or textbook.** The problem is: "If $5$ is added to $28/2$, what is the sum?" -> $5+14=19$. "The sum of $5$ and $28/2$ is...". However, the user wrote: "To solve the equation 5(28/2)..." And they wrote the multiplication. This implies the equation *is* $5 \times (28 / 2)$. **So the math is sound.** **But the Expert's Job is to be "In-Depth".** The "In-Depth" part requires acknowledging the context: 1. **Order of Operations:** The user identified the standard steps correctly. 2. **Conceptual Shift:** The user mentions "simplify as follows: 28/2 = 14". This is correct. 3. **Final Simplification:** "recognizing that 28 * 2.5 = 70 and 5 * 2.5 = 12.5". **This is the red flag.** * In the context of a standard math problem, **2.5** suggests a decimal context or a square root context (e.g., $\sqrt{625} = 25$, not $28 \times 2.5 = 70$ unless they meant $\sqrt{28 \times 28 \times \dots}$). * Wait, $28 \times 2.5 = 70$. This is true math. * BUT $5 \times 2.5 = 12.5$. This is also true. * Where does the confusion come from? The expert would say: "The key is to identify that the division ($28/2$) and multiplication ($5 \times$) can be combined logically. $5 \times (28/2)$ is a product of two numbers ($5$ and $14$). It is easier to calculate $14$ first. There is no need to break it down as $28$ and $5$ or as $28 \times 2.5$. The $2.5$ figure here likely comes from a different problem or is a confusion in the original text." **Let's construct the expert response.** The expert needs to: 1. Validate the steps. 2. Highlight the potential confusion in the "Related Math Problems" section (likely a copy-paste error from a user's textbook). 3. Confirm the math $5 \times 14 = 70$ is correct. 4. Address the "simplification" section gently, suggesting it might stem from a different problem type (e.g., $28/2 = 14$, then $5 \times 14 = 70$, or maybe they meant $\frac{5}{28} \times 2$?). **Wait, there is one more possibility.** Could the "Related math problems" be the *solution* to the original equation? No. Could the user be asking about **Exponent Rules**? $(a^m)^n = a^{mn}$. No. **Let's assume the user has a typo in the equation in their head but pasted the *text* of the equation.** If the user *meant* the equation $5 + 28/2$, the answer is 33. If the user *meant* the equation $28 / (5 \times 2)$, the answer is 2.8. If the user *meant* the equation $\frac{5}{2} \times 28$, the answer is 70. The expression given is exactly $5(28/2)$. **The calculation is correct.** **So the expert's thought process should focus on:** 1. **Verification:** Check $28/2 = 14$. Yes. Check $5 \times 14 = 70$. Yes. 2. **Clarification on "Simplification":** Point out that saying "28 * 2.5 = -
This is the augmentation using the “First Principles” prompt (2188 tokens):
## 1. Core Decomposition: First Principles Analysis To understand the logic, we must strip away the visual complexity of the fraction and the specific examples and look at the **algebraic structure** and **semantic rules** governing these problems. #### A. The Core Operations (The "Grammar") The text describes a fundamental operation of **multiplication** performed on the result of a **division**. * **Rule:** $A \times (B / C) = A \times B \div C$. * **Context:** The author intends to calculate the value of $28 \times 2.5$ (derived from $28/2 \times 5$) but uses a **fractional method** (multiplying by a fraction) which is mathematically equivalent but less intuitive for humans who expect base-10 arithmetic. * **Mechanism:** In this specific context, the logic is purely algebraic manipulation of numbers to produce a specific value. #### B. The Constraints (The "Rules") There are specific constraints governing the input numbers and the final output that are often missed in raw text analysis: * **Consistency:** The final answer ($d$) must be an **integer**. The text explicitly states $d = 70$ and $70/5 = 14$, implying the output must be a whole number. * **Contextual Specificity:** While general algebra applies, the numbers chosen ($28, 5, 28, 2$) are arbitrary. The problem asks *what value* $d$ must have, not just "solve for $d$." * **The "2.5" Anchor:** The author explicitly introduces the intermediate value **2.5** as a "key." This serves as the pivot point where the division ($28/2$) and the multiplication ($5 \times 14$) meet the requirement for the answer. #### C. The Assumptions (The "Epistemic State") These are the premises the text assumes the solver holds without realizing their necessity: 1. **Fraction Multiplication = Division:** The author assumes that $28 \div 2 = 28 \div 2$. In algebra, $a/b = (a \times b^{-1})$. The author equates this to multiplying the numerator and denominator by 1 (multiplying by 1.0) to "simplify." 2. **Integer Output:** The author assumes that if the final result ($d$) is an integer, the intermediate division step ($28/2$) must also yield an integer. 3. **Algebraic Equivalence:** The author assumes that $5 \times 28/2$ is fundamentally the same algebraic entity as $28 \times 2.5$, even if the visual representation changes. --- ### 2. Rebuilding from Scratch: The Algorithmic Journey Let's reconstruct this by acting as an engineer calculating $X = 28 \times 2.5$. We will follow the logic of the text step-by-step. #### Step 1: The Input We are given the expression: $$ 28 \times 2.5 $$ #### Step 2: The "Conversion" (Intuition) To the human mind, $2.5$ is not a raw number. It is **half**. We intuitively think of 2.5 as "5 divided by 2." $$ 28 \times 2.5 = 28 \times \left(\frac{5}{2}\right) $$ #### Step 3: The First Simplification (The Author's Choice) The author simplifies the numerator first to match the divisor: $$ 28 \times \left(\frac{5}{2}\right) $$ $$ \text{This becomes: } 28 \div 2 \times 5 $$ * **Why this works:** We multiply by 1 on top. $$ \frac{28}{1} \times \frac{1}{2} \times \frac{5}{1} = \frac{28 \times 5}{2 \times 1} = \frac{140}{2} $$ #### Step 4: The Second Simplification (The Crucial Step) The author changes the division of 2.5 into 2 and 0.5. $$ 28 \times \left(\frac{5}{2}\right) = 14 \times 5 $$ * **Why this matters:** This reveals the fundamental equivalence. Multiplying by a fraction of 1 (multiplying by $28/28$) and multiplying by a fraction of 2 (multiplying by $5/5$) results in the same final product. * **Result:** $14 \times 5$. #### Step 5: The Final Calculation Now we perform the multiplication. $$ 14 \times 5 = 70 $$ This result is an **integer**. #### Step 6: The "Alternative" Path (The Text's Twist) The text proposes a different path to get the same result, which is often faster for humans: 1. **Multiply directly:** $28 \times 2.5$. 2. **Convert 2.5:** $28 \times \frac{5}{2}$. 3. **Cross-cancel:** $28$ and $2$ share a factor of 2. 4. **Simplify:** $28 / 2 = 14$. 5. **Compute:** $14 \times 5$. 6. **Result:** $70$. --- ### 3. Analysis of Hidden Assumptions & Pitfalls By analyzing the text, we must identify where the logic holds up and where it breaks. **Assumption 1: "2.5" acts as a unit fraction.** * *Premise:* The author treats $2.5$ as $5/2$ immediately after calculating $14$. * *Critique:* Mathematically, $28/2 = 14$. If we plug this back into the formula: $$ \text{Formula} = \text{Numerator} \times \text{Dominator} $$ $$ 28 \times (5/2) = 14 \times 5 $$ This holds true regardless of whether we view $2.5$ as $5/2$. The *value* is the same. The author's shortcut relies on recognizing that $28/2$ is an integer ($14$), which allows the multiplication to be cleanly written as $(\frac{5}{1}) \times (\frac{28}{2})$. The logic is sound, but the *interpretation* is that 14 and 5 are the factors being scaled by 5, not that we are just multiplying fractions. **Assumption 2: Integer Output is Guaranteed.** * *Premise:* The author assumes that solving this algebraic problem yields an integer. * *Critique:* In the general world of algebra, $28/2 = 14$ is an integer. The *context* here implies the user wants the answer to be a whole number ($d$). However, does $28 \times 2.5$ *necessarily* result in an integer? * $28 \times 2 = 56$ (Integer) * $28 \times 2.5 = 70$ (Integer) * $28 \times 3 = 84$ (Integer) * *Counter-example:* If the input were $28/3$ instead of $28/2$, the result is $14/3 \approx 4.67$, which is not an integer. The constraint "Integer" in the text is a conditional assumption about the input numbers. **Assumption 3: The "Simplification" Rule ($x/y$ simplifies to $x \times 1/y$ if $y|x$).** * *Premise:* The text assumes $d = 70/5 = 14$. * *Implication:* This implies that for the final answer to be an integer, the final division ($70/5$) must also yield an integer. This is the **Consistency Constraint**. It means the author is implicitly assuming the result is an integer. ### 4. Final Conclusion The core logic is a clean application of **fractional arithmetic**: converting a decimal ($2.5$) into an equivalent fractional unit ($5/2$) and simplifying the expression to find an integer factor. The most critical takeaway for anyone solving this manually is: $$ 28 \times \frac{5}{2} = 14 \times 5 = 70 $$ If you encounter a similar problem like: $10 \times \frac{11}{3}$ * You must simplify the divisor: $10/3 = 10/3$. * You cannot simply multiply 3 by 3 to cancel out (unless you are doing integer division). * You must calculate $10/3 = 3.33...$ * Then multiply by 11: $3.33... \times 11 = 36.66...$ * *Note:* This result is a **non-integer**. The author's method would yield the **same** number ($36.66...$) in this case, but the *mechanism* is different. The key insight provided in the text is that the value is **70**. The confusion often arises because humans instinctively prefer base-10 arithmetic ($28 \times 2.5$). The text suggests that for the specific inputs provided ($28$ and $2.5$), the **fraction method is not just "simpler," it is *required* for the specific constraints of the problem.** -
This is the augmentation using “Rephrasing” (587 tokens):
### 1. Core Decomposition: Eliminating Indirect Operations The original equation $5 \times (28 / 2)$ is not merely a sequence of arithmetic operations; it is a specific instance of the distributive property in disguise. The hidden complexity lies in recognizing that the expression $28 / 2$ simplifies the fraction, allowing $5$ to act directly on the integer result rather than attempting to distribute across the denominator first. By isolating $28 / 2 = 14$ and applying the identity $5 \times 14 = 70$, we bypass the intermediate "division-by-fraction" risk and execute a direct numerical multiplication. This step transforms the problem from a procedural exercise into a clean evaluation of a specific value. ### 2. Contextual Alignment: Quantification of Shared Resources The scenario involving the TV station and the spread of DVDs highlights the structural similarity between the mathematical operation and a real-world distribution problem. The TV station sells DVDs at a fixed cost per unit, while the club purchases DVDs from various vendors. If the number of DVDs sold equals the number purchased, the profit calculation mirrors the algebraic structure. The hidden complexity involves identifying the variable "units of sales" as equal to the variable "units of purchase," which implies that the final dollar amount must reflect the total value of the shared items. ### 3. Logical Flow: Simplification Through Substitution To determine $d$ (the value of the DVD), the equation must resolve the fraction first. This is achieved by dividing the numerator $28$ by the denominator $2$, yielding the quotient $14$. Substituting this quotient back into the main equation $5 \times (28 / 2)$ forces the operation to reduce to $5 \times 14$. This reduction is logically equivalent to the step $d / 5 = 14$ derived from the equality between the total cost and the value per DVD, effectively solving for $d$ once the quotient is established. ### 4. Conclusion: Final Verification and Value Determination The final step requires verifying the result against the original constraints. We know that $d$ represents the value of one DVD, and $5$ is the cost per DVD. Therefore, $d$ must equal $70 / 5$, confirming that $5 \times (28 / 2) = 70 / 5$ holds true. The calculation $70 \div 5 = 14$ yields the integer value of the DVD's price, which is consistent with the original division $28 \div 2 = 14$. The equation remains valid because the left side of the equality ($5 \times 14$) and the right side ($70 \div 5$) both evaluate to the same integer.
Answer examples
-
GSM8k (5-shots with CoT):
Question: Cho hiked 14 kilometers per hour for 8 hours. Chloe hiked 9 kilometers per hour and stopped after 5 hours. How many kilometers farther did Cho hike? Target: `67` - original: strict=`27` (❌), flex=`27.` (❌), raw=`The distance covered by Cho hiked in 8 hours is 14 * 8 = 112 kilometers. The distance covered by Chloe hiked in 5 hours is 9 * 5 = 45 kilometers. The difference between the two distances is 45 - 112 = 27 kilometers. The ...` - first-principles: strict=`67` (✅), flex=`67.` (✅), raw=`The distance traveled by Cho is 14 * 8 = 112 km. The distance traveled by Chloe is 9 * 5 = 45 km. The distance traveled by Cho is 112 - 45 = 67 km. The answer is 67.` - tpt: strict=`67` (✅), flex=`67.` (✅), raw=`14 km/h * 8 h = 112 km Coe hiked 9 km/h for 5 h = 45 km So the distance between Cho and Chloe is 112 - 45 = 67 km. The answer is 67.` -
MATH500 (4-shot with CoT):
- Problem: What is the positive square root of the product $10 \times 15 \times 24$? - Target: `60` - - original: exact_match ❌, final=`None`, raw=`The product of the first three numbers is $10 \times 15 \times 24 = 3600.$ The product of the last three numbers is $24 \times 24 \times 24 = 10736.$ The product of the first two numbers is $10 \times 24 = 240.$ The product of the last two numbers is $24 \time...` - - first-principles-12B: exact_match ✅, final=`60`, raw=`$10 \times 15 \times 24 = 3600.$ The positive square root of $3600$ is $60.$ Final Answer: The final answer is 60. I hope it is correct.` - - tpt-12B: exact_match ✅, final=`60`, raw=`We can use the distributive property to rewrite the product as $10 \times (15 \times 24) = 10 \times 360 = 3600.$ The positive square root of 3600 is $\boxed{60}$. Final Answer: The final answer is 60. I hope it is correct.`
Discussion: synthetic pretraining vs distillation
A natural caveat in this line of work is the difficulty of cleanly separating synthetic pretraining from distillation. When the training corpus is rewritten by another model, the student learns not only from the original human-written data, but also from the generator’s decompositions, emphases, and stylistic choices. This concern is closely related to the framing of TPT, where thinking traces are generated by DeepSeek-R1-Distill-Qwen-7B, itself a distilled reasoning model.For more details, check the reviewer’s comments on the “Thinking Augmented Pre-training” submission to ICLR 2026 here.
In a broad sense, however, self-supervised pretraining is already a form of distillation: a next-token predictor compresses regularities from an upstream distribution into its parameters. With ordinary web text, that distribution reflects human language and problem-solving; with synthetic data, the teacher simply becomes more explicit. The relevant question is therefore not whether distillation is present, but what kind of signal is being distilled. Is the student mainly imitating teacher-specific surface behavior, or is the synthetic rewrite acting as a scaffold that makes underlying structure easier to learn?
Our results make a naive “copy the teacher” explanation less convincing. Our generator is a same-size 0.8B non-thinking model, yet synthetic augmentation still helps. The TPT paper similarly reports that a smaller 1.5B thinking generator outperforms the default 7B one, suggesting that generator strength does not straightforwardly determine synthetic data quality.
We therefore think the most useful framing is that synthetic pretraining lies on a continuum between dataset expansion and teacher distillation. At one end, synthetic rewriting improves learnability by making latent assumptions explicit, breaking large reasoning steps into smaller ones, and restructuring information into forms a smaller model can absorb more efficiently. At the other end, the student may inherit a recognizable teacher fingerprint, and part of the gain is effectively pretraining-time imitation. Disentangling these two effects remains an important open question.